曾经,世界首富们竞相购买游艇、私人飞机和私人岛屿。如今,他们的“规模”竞赛转向了计算集群。仅18个月前,OpenAI使用约25000个当时最先进的英伟达GPU网络训练了其顶尖的大型语言模型GPT-4。而现在,埃隆·马斯克和马克·扎克伯格正在展示他们的实力:马斯克表示已在一个数据中心部署了10万个GPU,并计划再添置20万个;扎克伯格则宣称将获得35万个。
这场为训练更强大AI模型而不断扩大计算集群的竞赛注定无法永续。每增加一个芯片不仅提升了处理能力,也加重了保持整个集群同步的管理负担。芯片数量越多,数据中心芯片用于数据传输的时间就越长,而实际工作时间则相应减少。简单地增加GPU数量只会带来递减的收益。
因此,计算机科学家正在探索更智慧、更高效的方法来训练未来的AI模型。解决方案可能在于彻底摒弃庞大的专用计算集群(及其高昂的前期投入),转而在多个较小的数据中心之间分配训练任务。一些专家认为,这或许是迈向更远大目标的第一步,即无需任何专用硬件即可训练AI模型。
训练现代AI系统的过程包括输入数据并隐藏其中部分内容,如句子或蛋白质结构。模型会尝试预测被隐藏的部分。如果预测错误,模型会通过一种称为反向传播的数学过程进行调整,以便在下次预测相同内容时更接近正确答案。
问题随之而来
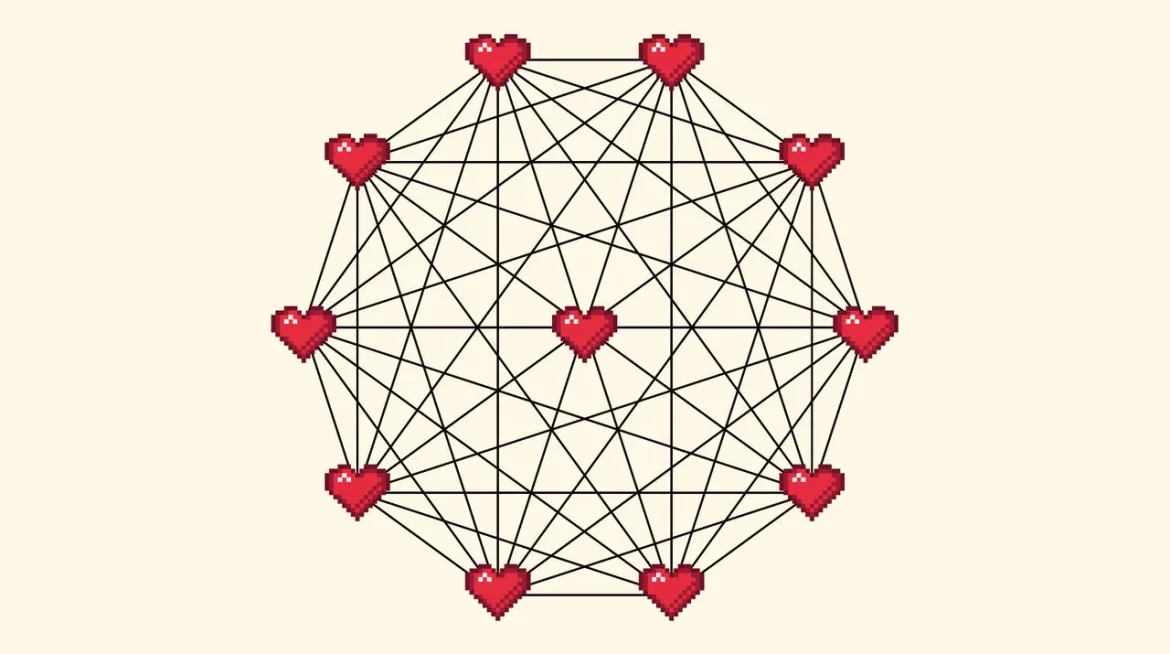
当需要“并行”工作时,让两个或20万个GPU同时进行反向传播,挑战就出现了。每完成一步,芯片都需要共享它们所做的修改数据。如果不这样做,就不是一次统一的训练过程,而是20万个芯片各自训练20万个独立的模型。这个被称为“检查点”的步骤会迅速变得复杂。两个芯片之间只需要一个连接,但20个芯片之间需要190个连接,而20万个芯片之间则需要近200亿个连接。检查点所需时间也相应增加。在大规模训练中,往往有一半的时间都耗费在检查点上。
 年付会员
年付会员 季付会员
季付会员本文由未来学人编译,原文作者:The Economist,审校排版:从林,点击查看原文链接
翻译作品,原文版权归原作者所有。未来学人仅提供翻译服务,不对原文内容或观点进行任何修改或代表。如有侵权,请联系我们删除。
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 